XFRM state
一. 简介
在Linux内核中,XFRM被用作IPsec协议的框架。
XFRM状态数据库存在于每个网络命名空间中。
这意味着在不同的网络命名空间中,可以存在不同的XFRM状态,它们之间相互隔离。这种设计使得在多个网络环境中同时运行IPsec等安全协议变得更加灵活和可行。
本文主要介绍网络命名空间中的XFRM状态数据库中的XFRM state——XFRM state是用于存储IPsec安全关联信息的数据结构。
- 网络命名空间下负责管理
xfrm state的字段 - xfrm state的存储方式——链表和哈希表的初始化
- 创建xfrm state
- 注册xfrm state节点
- 删除xfrm state节点
- 探讨站点到站点案例中 ICMP 报文的封装和加密过程
本文使用的内核版本为6.3.6。
本文中提到的命名空间均指网络命名空间或者netns。
二. netns下的XFRM
网络命名空间(netns)是一种将网络资源隔离开来的机制,每个网络命名空间都有自己的网络设备、IP地址、路由表和其他网络相关的资源。如果内核编译选项开启了CONFIG_XFRM,那么在struct net中就会多个叫做xfrm的字段。
1 | struct net { |
2.1 netns中的xfrm state
本文主要介绍struct netns_xfrm结构体中与xfrm state相关字段。
1 | struct netns_xfrm { |
每个netns下可以存在很多xfrm state节点,这些节点在被创建后都会注册到一个链表中。
为了快速地查找节点,内核会按照某些特定的查找方式将xfrm state节点加入到哈希表中。
state_all:是一个链表头,用于存储所有的XFRM state。state_bydst、state_bysrc、state_byspi、state_byseq:这些字段是指向哈希表头的指针,用于根据目的地地址、源地址、安全关联标识符(Security Association Identifier,SAID)和序列号来查找XFRM状态。state_hmask、state_num:state_hmask是一个哈希掩码,state_num是当前xfrm state的数量。state_hash_work:这是一个用于处理XFRM状态哈希表的工作队列。
2.2 xfrm state初始化
每当创建一个netns,都将调用xfrm_state_init()来对上一节提到的字段进行初始化。
1 | int __net_init xfrm_state_init(struct net *net) |
三. 添加一个xfrm state
我们将以站点到站点的案例来分析xfrm state
1 | 10.1.0.0/16 -- | 192.168.0.1 | === | 192.168.0.2 | -- 10.2.0.0/16 |
一对IPSEC VPN之间会建立两个xfrm state,在IKE(网络密钥交换)协议中我们也称为CHILD SA。一个是出方向的SA,一个是入方向的SA。
我在这里通过ip命令来查看一下moon站点的两个SA(xfrm state)
1 | moon:~# ip xfrm state |
向内核发起创建SA是由IKE协议来负责的,这里我们不展开描述,我们将从IKE进程发出XFRM_MSG_NEWSA开始,来分析xfrm state节点的创建过程。
3.1 xfrm_state
第二节我们介绍了一些管理xfrm state的字段,但都没有提及xfrm state节点的具体结构是什么样的。由于这个结构体比较大,本小结只会介绍最重要的一些字段。
1 | struct xfrm_state { |
1. id
每一个id都标识一个xfrm state,我们可以看下id由哪些参数构成:
1 | struct xfrm_id { |
2. sel
sel包含了一系列用于匹配数据包的条件,以便确定是否需要对数据包进行加密、认证或其他安全处理操作。
1 | struct xfrm_selector { |
3. props
xfrm state的一些参数
1 | struct { |
4. type
在xfrm_get_type()中,可以通过协议族和协议号来获取到相关的type,我的理解是type决定了安全关联的种类,常见的type如下:
1 | static const struct xfrm_type esp_type = |
ESP(Encapsulating Security Payload):
ESP协议提供了加密和认证机制,用于保护IP数据包的传输。它可以用于传输模式和隧道模式,并提供了对有效载荷的加密和认证功能。AH(Authentication Header):
AH协议提供了对IP数据包进行认证的机制,但不提供加密功能。AH可以用于传输模式和隧道模式,用于确保IP数据包的完整性和认证。
5. 算法相关
xfrm state中还记录了加密和认证算法
1 | struct xfrm_algo_auth *aalg; |
3.2 创建一个state
用户空间可以通过netlink命令字XFRM_MSG_NEWSA和XFRM_MSG_ALLOCSPI创建一个state实例。
- 首先检查用户空间的参数是否合法
- 其次创建state并向内核进行注册
- 最后调用通知链上的函数。
我们主要关注创建state和向内核注册的过程。
1. 创建state
在xfrm_state_construct()中会申请一块空间,并做一些默认初始化,然后将用户空间传入的参数拷贝到内核空间。拷贝的主要内容就是3.1节我们提到的一些字段。
主要包括:
- id:用以唯一标识一个节点
- sel:流量筛选器
- props: xfrm state相关的参数,例如源地址、传输模式、隧道模式
- lft: 生存周期
- aalg:注册算法
- ealg:加密算法
- geniv:加密算法的初始化向量
2. 初始化state
接下来会根据目前已知的state信息,在__xfrm_init_state()做一些初始化。
我们会根据用户空间对这个SA type的配置,来调用相关type的初始化函数。
例如本例中用户要求的type为esp,协议族为IPv4,那么就会调用esp4模块注册的init_state回调函数。这里不再展开描述。
3. 注册state
初始化完毕后,将会调用__xfrm_state_insert()将xfrm start节点进行注册。
1 | static void __xfrm_state_insert(struct xfrm_state *x) |
4. 通知
最后会在km_state_notify()调用通知回调函数
1 | list_for_each_entry_rcu(km, &xfrm_km_list, list) |
四. 删除xfrm state
使用ip xfrm state flush命令可以清除所有的xfrm state,也可以设置过滤规则清除指定xfrm state。
不论如何,最后都会调用到__xfrm_state_delete()来清除这个xfrm state。
如果我们需要真正区释放调这块空间的话需要指定sync,否则的话内核仅仅把这个节点从这种表中摘除,同时把这个节点添加到一个垃圾回收链表中(gclist)。
1 | static DECLARE_WORK(xfrm_state_gc_work, xfrm_state_gc_task); |
内核的垃圾回收机制会定期调用xfrm_state_gc_task()来释放内存。
五. 观察一个分组的加密过程
从本节开始,将介绍XFRM框架下如何使用XFRM state来对分组进行安全处理。
XFRM框架除了state外还有一个policy,policy负责匹配分组是否进入XFRM流程,后续会出一个XFRM policy的文档,在此文中,了解到协议栈会根据policy来选择是否将分组交给XFRM来处理就够了。
所以,后文的介绍默认协议栈已经经过了policy的匹配,确认分组需要交给XFRM,那XFRM要如何处理这个分组呢?我们提出以下问题:
- 是需要使用传输模式还是隧道模式呢?
- 是需要使用ESP封装还是使用AH封装呢?
- 如需加密,应该使用哪种算法套件呢?
这些问题的答案都存储在了XFRM state中。这意味着我们需要从policy中寻找线索,使用这些线索,来在XFRM state中查找答案。
policy中的线索就是一个名为template的模板,我们将使用这个模板,在netns中的XFRM state节点中去匹配,找出匹配的XFRM state。事实上,IPsec策略通常由多个因素组成,包括源地址、目标地址、传输层协议等。当进行策略匹配时,可能会有多个xfrm state与给定的策略条件匹配,这可能导致匹配深度的增加。XFRM_MAX_DEPTH的存在就是为了限制这种情况的发生。它确保了在进行策略匹配时,系统不会无限递归地搜索和匹配xfrm state,从而避免潜在的性能问题。
但是我们本文只介绍最简单的环境,一个template只能匹配到一个XFRM state。
5.1 IPSEC场景
本文将分析最传统的站点到站点之间建立IPSEC的案例。两个站点为moon和sun。
两个站点之间建立了使用ESP封装的隧道(即mode为tunnel,type为ESP4)。
两个站点将保护各自子网中的流量。
1 | 10.1.0.0/16 -- | 192.168.0.1 | === | 192.168.0.2 | -- 10.2.0.0/16 |
当隧道建立好以后,我们使用moon-net中的一个主机alice(10.1.0.10)来ping sun-net中的一个主机bob(10.2.0.10)。
- 有效载荷为ICMP数据——data
- 内层的原始IP头为:Internet Protocol Version 4, Src: 10.1.0.10, Dst: 10.2.0.10 —— Original IP Header
- ESP Header
- 外层站点的IP头为:Internet Protocol Version 4, Src: 192.168.0.1, Dst: 192.168.0.2 —— Outer IP Header
最终的IP Packet格式如下:
1 | ----------------------------------------- |
由于moon站点收到了目的地址为10.2.0.10的IP Packet,所以协议栈会转发这个数据包。
我们现在应该位于网络层的ip_forward()处。
5.2 查找state
从现在开始,我们将从通过模板查找state开始,追踪这个分组的生命。
入口函数为xfrm_state_find()。
1 | struct xfrm_state *xfrm_state_find(const xfrm_address_t *daddr, |
daddr为192.168.0.2,saddr为192.168.0.1,在查找xfrm state的时候还会结合tmpl->reqid这类标记,在netns中通过net->xfrm.state_bydst这个哈希表来快速匹配state。最终会使用tmpl中的字段和xfrm state中的sel字段进行精准匹配。
结果就是匹配到了一个合适的xfrm state并返回。那么针对这个分组的安全处理方法就都拿到了。
5.3 创建dst_entry
struct dst_entry是用于表示网络数据包转发信息的结构体。它包含了一系列字段,用于描述数据包的转发目标、路径和相关信息,我们将重点关注他的output。
XFRM框架最后也需要给协议栈返回dst_entry来让协议栈继续处理数据包,但是在XFRM框架中,对这个结构体作了扩展,这也是c语言中对继承的一种表示方法。
XFRM中有一个结构体继承自dst_entry,他叫struct xfrm_dst。
1 | struct xfrm_dst { |
这个结构体用于表示一组要应用于某个数据流的转换。将路由、xfrm policy、xfrm state进行了关联。
在对xdst实例化的过程中,将向dst_entry注册XFRM框架的ops。在xfrm_alloc_dst()中完成了这种注册。
而决定协议栈下一层应该使用什么处理函数的是dst_entry的output字段。
1 | afinfo = xfrm_state_afinfo_get_rcu(inner_mode->family); |
这个afinfo是通过xfrm_state_register_afinfo()注册的。对于IPv4,注册的函数为:
1 | static struct xfrm_state_afinfo xfrm4_state_afinfo = { |
这里我们总结一下:
- 协议栈对分组进行了xfrm policy的匹配
- XFRM模块通过policy中的模板,与XFRM state中的sel进行了匹配
- 得到一个(可能有多个)xfrm state
- XFRM模块将创建一个继承自dst_entry的结构xfrm_dst
- xfrm_dst将XFRM state、XFRM policy组织起来
- xfrm_dst将返回一个网络数据包转发信息的结构体dst_entry
- dst_entry中包含了协议栈下一层要使用的处理函数skb_dst(skb)->output
- skb_dst(skb)->output在此时为xfrm4_output
5.4 ip_forward_finish
通过之前的匹配、查找与注册,网络转发层已经知道这个分组要怎么处理了,他会调用dst_output来进一步处理分组。
1 | static inline int dst_output(struct net *net, struct sock *sk, struct sk_buff *skb) |
这个宏定义在IPv4中展开是这样的:
1 | likely(skb_dst(skb)->output == ip_output) |
我们目前处于第二个分支,我们的output函数为xfrm4_output
5.5 xfrm4_output
沿着函数调用一路追下来,可以看到最终的核心处理函数在这里:
- 首先调用
xfrm_output_one()处理分组 - 其次调用dst->ops->local_out
- 最后检查skb_dst(skb)->xfrm字段,为空表示处理完XFRM框架了,直接通过
dst_output()送往下一层
1 | int xfrm_output_resume(struct sock *sk, struct sk_buff *skb, int err) |
5.6 local_output
我们稍后在沿着xfrm_output_one()进行分析,这一次我们站在一个更高的角度来看分组的生命周期。
还记得这个dst是怎么生成的吗?他在xfrm_alloc_dst()中注册了XFRM框架的dst ops:
1 | static struct dst_ops xfrm4_dst_ops_template = { |
所以skb_dst(skb)->ops->local_out()就是__ip_local_out(),这也意味着XFRM框架已经完成了tunnel封装和ESP加密了,不难猜测,xfrm_output_one()中所做的就是完成tunnel封装和ESP加密。
1 | int __ip_local_out(struct net *net, struct sock *sk, struct sk_buff *skb) |
可以看到,目前skb->protocol指明为ETH_P_IP,然后将IP Packet送往下一层。此时skb_dst(skb)->output的回调函数就是ip_output(),至此,我们完整地处理完了ipforward动作。
六. 封装与加密
让我们回归xfrm_output_one(),看一下这里发生了什么。
1 | static int xfrm_output_one(struct sk_buff *skb, int err) |
总体上是一个do while,在IPSEC中是存在内层IP和外层IP的说法的,所以这个截至条件就是外层IP的mode不再是tunnel(这是否意味着可以像套娃一样套很多层呢?)。
接下来看一下循环的主要流程:
- xfrm_outer_mode_output:添加外层IP头
- xfrm_type_output:进行ESP加密
6.1 封装
我们主要关注隧道模式的封装,它是在xfrm4_tunnel_encap_add()中完成的。
1 | static int xfrm4_tunnel_encap_add(struct xfrm_state *x, struct sk_buff *skb) |
我们看一下原始的Packet,如果skb->head为0的话,64到78刚好为14字节的Eth header,78到98刚好是IP header,98开始就是ICMP负载了。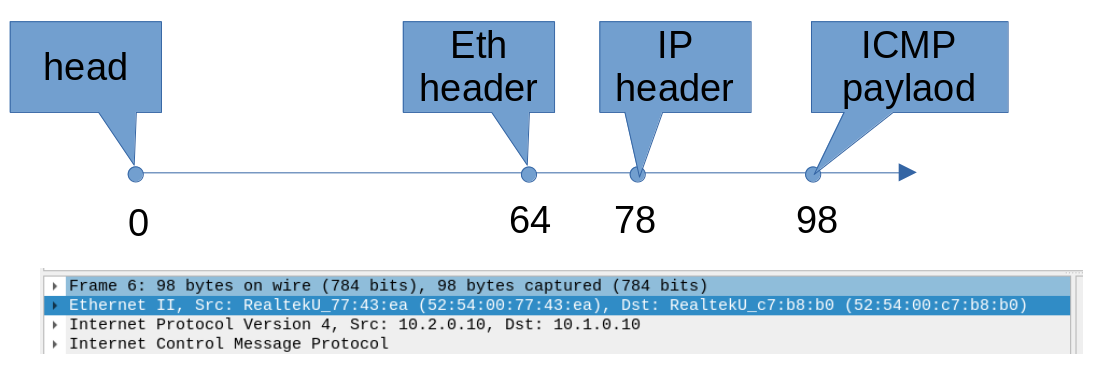
他主要分为以下操作:
- skb_set_inner_network_header:用inner_network_header指向network_head,表示这个IP Packet的外层IP报文头现在只是内层IP头了。
- skb_set_network_header:更新外层IP头相对于内层IP头的偏移。
- 更新mac_header相对于外层IP头的偏移。
- 通过
iphdr()拿到指向外层IP头的指针 - 初始化外层IP头,包括长度、协议、源目IP地址等。
此时,经过tunnel的封装,我们的skb中的一些指针状态将变为以下的样子。
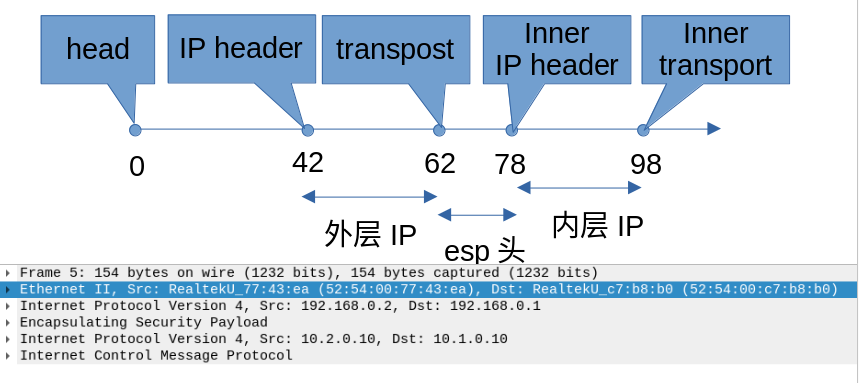
6.2 加密
在完成隧道的封装以后,XFRM将交给之前注册的type模块来处理分组——x->type->output(x, skb)。
还记得这个type是在哪里进行注册的吗?我们在3.2.2节中简单提到了在创建好XFRM state之后会调用__xfrm_init_state()对state进行初始化。也就是在这里注册了type的output函数。
1 | static const struct xfrm_type esp_type = |
所以,我们进入了ESP模块,看下他是怎么创建ESP封装与加密的。
1 | static int esp_output(struct xfrm_state *x, struct sk_buff *skb) |
- 首先修改了mac header,IPPROTO_ESP为50
- 填充esp header
- esp_output_tail进行加密认证
1. 封装
通过上面的图片,我们可以看到在封装外层IP的时候,预留了16字节的空间,交给了transport_header,所以ip_esp_hdr()是用的skb_transport_header()来拿到的地址
1 | static inline struct ip_esp_hdr *ip_esp_hdr(const struct sk_buff *skb) |
拿到esp头后会填充spi、seq和IV等字段。
2. 加密
加密前会先封装一个加密请求,最终调用crypto_aead_encrypt()进行加密。
从组织加密请求到调用加密算法看着非常晦涩,我就先跳过了。
1 | int esp_output_tail(struct xfrm_state *x, struct sk_buff *skb, struct esp_info *esp) |